|
|
1.资料名称:2025-2000年上市公司企业数据资产数据、数据资产情感分析数据
2.测算方式:参考C刊《经济管理》苑泽明(2025)老师研究的做法,第一, 构建底层逻辑选取种子词, 利用机器学习法扩充种子词, 形成 “数据资产” 词典。首先,鉴于数据资产化是企业无序、 低价值数据向结构化、 可应用的高价值数据转化, 本文依据数据价值链理论, 以 “数据资产获取-数据资产处理-数据资产应用” 价值链为底层逻辑, 初步选取数据资产种子词; 其次, 中国信息通信研究院指出, 数据资产是以电子或其他方式记录的结构化或非结构化数据①, 本文对数据记录方式的相关关键词是否纳入种子词进行补充检验。再次, 基于 《“十四五”数字经济发展规划》 和 《“十四五” 大数据产业发展规划》 等官方文件, 依据其数据资产关键词对比分析种子词, 以确保完整性与精准性, 在此基础上, 通过向学术界、 大数据行业协会以及相关企业人员征询意见, 调整、 完善种子词。最后, 利用自动短语提取法 (Autophrase) 扩展种子词, 形成数据资产词典根据数据资产词典, 使用计算机编程语言 (Python) 对上市企业披露的年度报告进行相关词汇的词频统计, 并利用情感极性分析技术 (SnowNLP) 对文本数据进行分词、 向量化处理, 得到经情感极性分析调整后的词频。本文将表达正向与中立的词频加总, 为避免数据的右偏性, 使用对数化处理之后的总词频度量数据资产水平
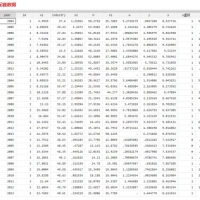
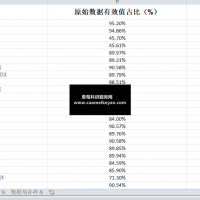
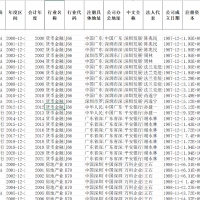
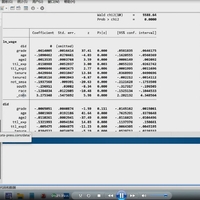
3.资料范围:7万多个样本(2.4万个非0值,有些企业是没有数据资产或者数据资产为负向,属于正常现象),5800多家企业,包括原始数据、计算代码和最终计算结果,大家可以验证一下确保准确性!
4.参考文献:
苑泽明,黄灿,李萌,等.企业数据资产与资本市场价值发现[J].经济管理,2025,47(03):64-84.DOI:10.19616/j.cnki.bmj.2025.03.004.
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有帐号? 建议用  立即注册 立即注册
x

|




 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2024-8-16 10:34:02
发表于 2024-8-16 10:34:02
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜