|
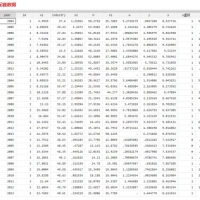
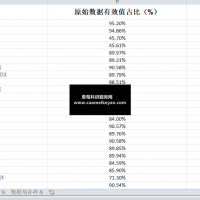
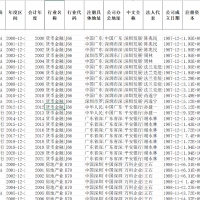
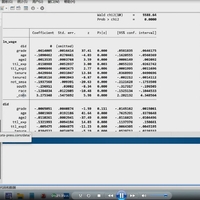
1、资料名称:2024-2001年上市公司企业数智决策程度数据、企业数智决策数据(大语言模型) 2、测算方式:参考c刊《国际贸易问题》徐苗(2026)老师的做法,本文采用级联处理策略(Cascading Strategy)进行本次文本分类任务, 依次选取BERT 和 ChatGLM2 - 6B 分两阶段进行。 BERT 兼具语义理解能力与高处理效率,ChatGLM2-6B 作为生成式大语言模型, 则能结合训练数据与合理设计的 Prompt(提示词)更为精准地理解语义间的微妙区别。 因此, 本文首先在第一阶段运用 BERT对 113 万条文本进行初筛, 使用前述训练集和开发集构建模型。 在第一轮筛选中,BERT 在测试集上的预测结果达 98%的召回率, 表明该模型能将 98%包含数智决策实践的文本筛选出来。基于两大模型对 113 万条文本数智决策实践的识别结果, 参考现有文献对关键词词频处理惯例, 将企业当年年报中含数智决策的自然段落数量加 1 后取自然对数, 生成数智决策程度指标(DDDM) 3、资料范围:6.5万多个样本,5600多家企业,包括原始数据、计算代码、计算过程部分截图(确保是代码真实测算出来的)及最终结果,大家可以验证一下确保准确性! 4、参考文献: 徐苗,金衍义,卢俊峰,等.数智决策与企业出口关系稳定性——基于大语言模型的微观证据[J].国际贸易问题,2026,(02):150-169.DOI:10.13510/j.cnki.jit.2026.02.008.
| 



 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2026-3-11 10:01:55
发表于 2026-3-11 10:01:55


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜