|
|
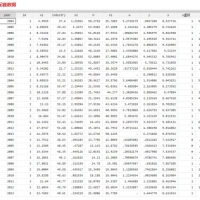
1.资料名称:2025-2001年上市公司企业供应链中断风险数据、企业供应链中断风险水平
2.测算方式:参考《南开管理评论》江伟(2024)老师的做法,
首先获取MD&A文本语料。
其次构建供应链中断风险种子词集,具体包括:“供应链”、“供应商”、“供应”、“供需”、“上游”、“下游”、“采购”、“成本”、“原材料”、“价格上涨”、“减产”、“紧缺”、“囤货”、“储备”、“故障”、“经营风险”、“中断”、“停工”、“运费”、“运力”。
然后训练模型,更好地识别上市公司年报MD&A部分上下文的语义信息,并且能够通过计算向量的余弦相似度获得种子词的语义相似词,为构建词典奠定基础。
随后形成供应链中断风险词集,将第二步确定的20个种子词输入在第三步骤中训练好的模型中,初步得到200个供应链中断风险的关键词,根据相似度大于0.6的要求进一步对上述200个关键词进行筛选,最终确定出70个供应链中断风险的关键词,由此形成本文的供应链中断风险词集。
最后计算供应链中断风险指标,将年报MD&A文本进行停用词和非中文词清理之后,计算总词数与供应链中断风险关键词的词频;计算MD&A部分供应链中断风险词集中关键词出现的词频占MD&A文本总词数的比例,由此得到企业层面的供应链中断风险的代理指标SCDRisk1。
本文也分别采用相似度大于0.5和0.7的要求来确定最终的供应链中断风险的关键词,采用上述相同方法得到企业层面的供应链中断风险的两个替代指标SCDRisk2 和 SCDRisk3。
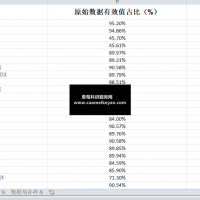
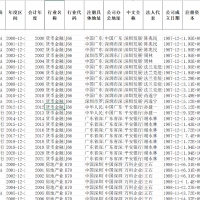
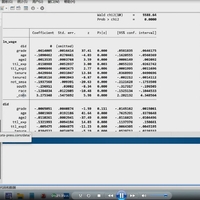
3.资料范围:5700多家企业,7万多个样本(数据非常完整,大家可以任意对比),附带原始数据、计算代码、计算代码视频录制(确保代码真实可向期刊公开,非自己主观生成,由于运行时间过长占用太多内存,因此有开始和结束部分)和最终计算结果,大家可以验证一下确保准确性!
4.参考文献:江伟,王楠,曹少鹏.供应链中断风险的度量与应用:基于词嵌入模型的分析[J/OL].南开管理评论,1-34[2024-12-20].
此数据为科研课题组自用数据,非仅仅只有一个结果胡编乱造,真正的原创一手认真整理数据,2025年数据已经更新,欢迎大家下载!
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有帐号? 建议用  立即注册 立即注册
x

|




 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2024-12-22 10:18:22
发表于 2024-12-22 10:18:22
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜 楼主
楼主